There is a saying attributed to Edison that goes something along the lines of “I have not failed–I have just found 10,000 ways that don’t work.”
The goal of the project was to optimize a selected open-source compression or checksum package and produce a meaningful improvement in performance. I chose lrzip, partly because it seemed interesting and partly because its creator is a physician, which is a career that I had at length considered myself back in high school before deciding that hospitals and life-and-death situations are scary. This might not have been the best choice (nor, I guess, the best reason to make a choice) because, well, lrzip looks pretty good. I could find no area of optimization that would amount to a substantive improvement. Whenever I thought I had come across an opportunity, it turned out not to be the case at all.
Optimization, I’ve come to realize, is pretty hard. Conversely, making a program run worse, even unintentionally, is very easy.
In phases one and two of this project I noted that lrzip crashed on AArch64 platforms when compressing a file with ZPAQ due to ZPAQ’s use of x86-specific JIT code. I thought to translate the x86 instructions into ARM instructions, so that JIT code could be used on both architectures, but that was too tall an order. I chose instead to focus on the C++ code that is used when JIT is unavailable, to try to optimize it and bring its runtime closer to that of the JIT version of the program. Also, I examined the LZMA code in the package (as LZMA is the default compression algorithm lrzip uses) and tried to optimize that as well.
Now, let me count the 10,000 ways.
The first order of business was to profile the program in order to see which functions took up the majority of the execution time. gprof was the tool for this. First I built the package with the -pg flag, which generates extra code to write profile information. This I did by setting it as one of the C, C++, and linker flags when calling the configure script:
[andrei@localhost lrzip-master]$ ./configure CFLAGS="-pg -O2" CXXFLAGS="-pg -O2" LDFLAGS="-pg"
Then I built the package using make (made the package?) and then ran lrzip on a 500MB text file.
[andrei@localhost lrzip-master]$ ./lrzip text Output filename is: text.lrz text - Compression Ratio: 3.937. Average Compression Speed: 2.041MB/s. Total time: 00:04:04.53
This generated a gmon.out file in the directory, which lets us examine lrzip using the gprof tool. I used the following command to create an image from the profile information:
[andrei@localhost lrzip-master]$ gprof lrzip | gprof2dot | dot -Tpng > image.png
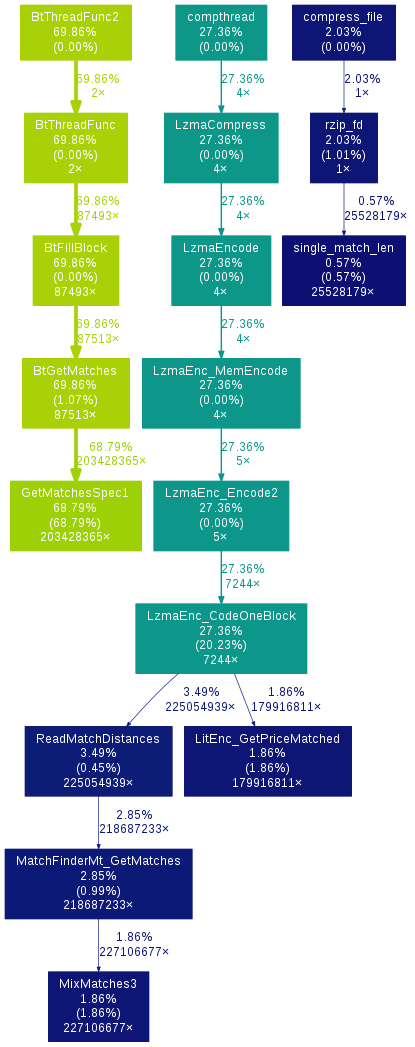
We can see from the graph that the program spent the vast majority of its time in the function GetMatchesSpec1, which is defined in the file lzma/C/LzFind.c. The graph tells us that the function was called 200 million times, so I figured that any marginal improvement I could make to the function would result in a significant gain in performance.
The function uses two Byte pointers to move along the stream of data read from the text file, and two UInt32 pointers (typedef’d as CLzRef) to keep track of matches from the data in a circular buffer.
CLzRef *ptr0 = son + (_cyclicBufferPos << 1) + 1; CLzRef *ptr1 = son + (_cyclicBufferPos << 1);
Since the two pointers point to adjacent data locations I tried to define one in terms of the other (removing the “+1” part of ptr0’s definition then setting ptr1=ptr0++), but it had no effect, and I think the machine code generated would be the same regardless.
if (++len != lenLimit && pb[len] == cur[len])
while (++len != lenLimit)
if (pb[len] != cur[len])
break;
This I rewrote as a single while loop, but as I said in phase two it had no (or a negative) effect on the executable. The objdump revealed that both this code and my edit resulted in identical instructions with only a slight change in layout.
I also rewrote this section of the code entirely to check multiple bytes at a time by XORing chunks of data from pb and cur, but even before fine-tuning the code to set len to the proper value after the first different chunk of data was found, I realized that the overhead of doing all this made the program significantly slower, so I abandoned that course of action. (For the text file, the loop only ran a few times with every function call, so checking very large chunks of data would be counter-productive).
After that, I tried to see if I could find something to optimize in LzmaEnc_CodeOneBlock, which is in lzma/C/LzmaEnc.c. I couldn’t, at least not beyond that failed experiment with memmove that I wrote about in phase two.
So, LZMA I couldn’t make better. I then went back to ZPAQ. Here’s the profile information for lrzip when it’s invoked with the -z flag after having been compiled with -DNOJIT to turn off the JIT code:

Both update0 and predict0 are structured as a for loop that uses a switch statement to check the value of an element of an array, which gets its value from an element in the block header array of a ZPAQL object, which represents ZPAQL instructions. I couldn’t find any way to optimize the functions without breaking the logic of the algorithm. The only thing I could do is replace some multiplication operations with bitshifts, but that didn’t affect the runtime (I think the compiler does that as well, if it can).
The execute function, which consists of a switch statement of over 200 cases, only takes up 3% of the execution time, and as much as I tried to optimize it I couldn’t get it to run more quickly by any measurable magnitude, so that didn’t work out either.
My attempts to edit the source code having been unsuccessful, I tried to see if any compiler options would make the program go faster, and, indeed, -Ofast (which enables -ffast-math) created an executable whose LZMA compression consistently outperformed the default -O2 executable by about 1% without introducing any errors into the compressed file. -ffast-math, though, is probably not something one would want in a compression tool, and there might be potential for mathematical errors somewhere in the code. Besides, the 1% difference, though I tested it quite a few times, might just have been a coincidence.
In the end, all I could do is add a small preprocessor condition in the libzpaq/libzpaq.h file to check for an x86 architecture and disable the JIT code if none is found. I created a patch file but I am not sure if it’s worth submitting since 1) it is such an insignificant change and 2) it only checks for GCC and Visual Studio macros, and if the program is compiled on an x86 processor with a different compiler then the JIT code will be deactivated, which will have a significant negative impact on performance. Here is the patch file for, at least, posterity:
From 3976cdc2640adbe593a09bba010130fcf74ef809 Mon Sep 17 00:00:00 2001 From: Andrei Topala <atopala@myseneca.ca> Date: Thu, 21 Apr 2016 17:56:34 -0400 Subject: [PATCH] Added a preprocessor check for an x86 architecture in libzpaq.h as a requisite for enabling JIT code. --- libzpaq/libzpaq.h | 5 +++++ 1 file changed, 5 insertions(+) diff --git a/libzpaq/libzpaq.h b/libzpaq/libzpaq.h index 93387da..e2b5058 100644 --- a/libzpaq/libzpaq.h +++ b/libzpaq/libzpaq.h @@ -25,6 +25,11 @@ comprises the reference decoder for the ZPAQ level 2 standard. #ifndef LIBZPAQ_H #define LIBZPAQ_H +// If we're not on an x86 processor, disable JIT +#if !defined(i386) && !defined(_M_IX86) && !defined(__x86_64__) && !defined(_M_X64) +#define NOJIT +#endif + #ifndef DEBUG #define NDEBUG 1 #endif -- 2.5.5
That concludes this chapter in our journey through the wide waters of software portability and optimization. SPO600 was certainly the most challenging and most interesting course I’ve taken at Seneca, and I am sure I learned very much. I do wish I’d had more time to blog about it, though. That is my only regret, and also the 10,000 failures.
